
Cybersecurity Frameworks: NIST, ISO, and COBIT
Cybersecurity frameworks don’t fail because they’re “too complex.” They fail because organizations treat them like a document to satisfy instead of an operating system to run. If you’ve ever had a board asking, “Are we secure?” while your team can’t even explain where the evidence lives, you’ve felt that gap. This guide breaks down NIST, ISO, and COBIT in practical terms—what each is best at, where they overlap, and how to implement a single control system that supports audits, reduces risk, and scales with modern threats (especially across cloud, SaaS, and remote teams).
1) Frameworks aren’t checklists: they’re decision systems you run weekly
Most organizations “adopt” a framework the same way they “adopt” a gym membership: they pay for the idea of being fit. They publish a policy, run a gap assessment, and call it progress. But the attackers don’t care about your policy library; they care about how fast you detect, how cleanly you contain, and how reliably you recover—especially as identity attacks surge and lateral movement accelerates. That’s why your framework choice must map to real operational pain: visibility, accountability, and repeatability.
Here’s what frameworks actually do when implemented correctly:
Create shared language between security, IT, finance, and leadership so risk is measurable (not vibes).
Define minimum operating standards so teams aren’t improvising controls during incidents.
Standardize evidence so audits and third-party requests don’t trigger fire drills.
Enable prioritization so you can fund what matters instead of what screams loudest.
If you’re building toward long-term resilience, treat frameworks like a forecasting tool: a way to spot weak signals early—before they become a headline. That mindset aligns naturally with threat forecasting work like top 10 cybersecurity threats predicted to dominate by 2030 and the “what changes next” lens in ai-powered cyberattacks: predicting future threats & defenses 2026–2030. It also prevents the common trap of buying tools without a control strategy—especially when your monitoring architecture is fragile or mismatched (see next-gen SIEM: future cybersecurity technologies you need to watch 2026–2030 and security information and event management (SIEM): an overview).
A framework is valuable only when it drives weekly behaviors:
What does “secure access” mean in your org this quarter?
Which systems are “crown jewels,” and do your controls actually reflect that?
What evidence proves controls work today, not last year?
Who owns remediation when issues cross teams?
If your answers rely on one hero engineer, you don’t have a framework—you have a personality-driven security program that collapses under turnover. That’s exactly why career-grade operational maturity matters (and why many teams formalize roles via structured paths like complete guide to becoming a SOC analyst (2025) and from SOC analyst to SOC manager).
2) NIST vs ISO vs COBIT: choose based on what you’re trying to fix
A fast way to stop framework confusion is to categorize them by job-to-be-done:
NIST: best when you need operational clarity and security outcomes
If your pain is “we don’t have a consistent way to detect and respond,” NIST-style thinking helps because it speaks in functions and outcomes. That’s critical when your environment is shifting—cloud workloads, SaaS sprawl, remote access, and identity-first attack paths. NIST also pairs naturally with modern detection programs, especially if you’re evolving your stack beyond “log everything” into “detect what matters” (see security information and event management (SIEM): an overview and predicting advances in endpoint security solutions (by 2027)).
NIST also helps you reason about the why now of threats—identity takeover, cloud compromise, and ransomware evolution (use predicting the next big ransomware evolution (by 2027) alongside ransomware detection, response, and recovery to anchor controls to real attack behavior).
ISO 27001: best when you need management discipline and repeatable evidence
If your pain is “we cannot survive audits, customer security questionnaires, or regulator scrutiny,” ISO-style discipline is powerful because it forces an ISMS mindset: defined scope, ownership, documented processes, continual improvement, and traceable evidence. That’s especially valuable as compliance evolves and becomes more continuous (see future of cybersecurity compliance: predicting regulatory trends by 2030 and predicting future cybersecurity audit practices).
ISO tends to expose the uncomfortable truth: many “controls” exist only in people’s heads. If your program collapses when one security engineer is on vacation, ISO forces you to formalize processes that keep working.
COBIT: best when you need enterprise governance across IT and business
If your pain is “security can’t get traction—priorities shift weekly, remediation stalls, ownership is unclear,” COBIT is a governance accelerator. It’s strongest when security isn’t just a security problem; it’s an enterprise accountability problem. COBIT helps define decision rights, measure maturity, and connect security priorities to business outcomes so you can stop fighting for basic hygiene.
COBIT becomes especially relevant when your risk spans multiple domains: cloud, identity, third-party, and business processes (like finance approvals)—which is why it pairs naturally with emerging fraud vectors such as deepfakes (see deepfake cybersecurity threats: how to prepare (2026 insights) and broader sector pressure like cybersecurity trends in finance).
A practical takeaway: most mature programs use all three—but not as three separate programs. You run one control system and map it to the other frameworks when needed.
3) The “one control set” approach: build once, map everywhere
If you want speed and defensibility, stop building separate framework workstreams. Create one internal control system with three layers:
Control statements (what must be true)
Implementation standards (how you do it here)
Evidence and tests (how you prove it works)
This is where many teams quietly fail: they write controls in vague language (“appropriate measures shall be taken”) that can’t be tested, then they wonder why audits hurt and incidents spread.
Step 1: Define your crown jewels and business services
Start with what can’t fail: revenue systems, customer identity, payment flows, production environments, regulated data, and critical availability services. If you don’t define this, your controls will be evenly distributed—and evenly useless.
For cloud-heavy orgs, this is inseparable from cloud security architecture (see future of cloud security: predictive analysis of key trends and the role reality in how to become a cloud security engineer). For zero trust roadmaps, align service criticality with identity and segmentation strategy (see predicting the future of zero trust security and threat direction in ai-driven cybersecurity tools: predicting the top innovations).
Step 2: Write controls that are testable and ownership-ready
A good control has:
Owner (single accountable role)
Scope (systems, data, or teams)
Cadence (continuous/daily/weekly/quarterly)
Evidence (what artifact proves it)
Failure condition (what “broken” looks like)
Example (Identity):
Control: “Privileged access requires phishing-resistant MFA, is time-bound, and is reviewed quarterly.”
Evidence: “PAM report + MFA policy + quarterly access review minutes + exceptions list.”
Failure condition: “Any permanent admin role without review in 90 days.”
This is how you protect against identity takeover patterns that are getting worse, not better (connect your thinking to broader threat forecasting like top 10 cybersecurity threats predicted to dominate by 2030 and evolving attack automation in automation and the future cybersecurity workforce).
Step 3: Build an evidence system that doesn’t rely on heroics
If you dread customer questionnaires, you don’t have a security problem—you have an evidence retrieval problem.
Create an “evidence map”:
Control ID → Evidence artifacts → Source system → Owner → Update cadence → Retention period
Then store evidence in one place with predictable naming and access controls.
Your evidence system should integrate with operational tools like SIEM, ticketing, IAM, vulnerability scanning, and backup validation (and it should survive the reality of modern infra: SaaS, cloud, remote endpoints). This also aligns naturally with audit modernization trends (see predicting future cybersecurity audit practices and compliance trajectory in future of cybersecurity compliance).
4) Implementation playbook: how to operationalize frameworks without bureaucracy
Frameworks turn into bureaucracy when you do them top-down only (policies) or bottom-up only (tools). The professional implementation path is a middle route: governance that creates clarity, and operations that create proof.
Build a cadence that forces decisions
A strong program has a repeatable cycle:
Weekly: control health review (top failures, exceptions, active remediation)
Monthly: risk review (new threats, business changes, vendor changes)
Quarterly: access reviews, recovery testing, tabletop exercises, maturity reassessments
Annually: scope review, control redesign, strategic roadmap refresh
This cadence matters because the threat landscape evolves faster than annual audits (see forward-looking threat pressure like ai-powered cyberattacks 2026–2030 and identity-adjacent fraud expansion like deepfake cybersecurity threats). Your framework must be a living instrument, not a once-a-year report.
Start with “high leverage” controls that collapse attacker options
If you’re overwhelmed, prioritize controls that reduce multiple attack paths at once:
Phishing-resistant MFA and strong session protections (identity takeover resistance)
Privileged access controls (reduce blast radius)
Logging + detection use-cases (reduce dwell time)
Backup immutability + restore testing (ransomware resilience)
Cloud guardrails (reduce misconfig + permission drift)
Tie these to practical capabilities your teams already recognize: endpoint resilience and detection maturity (see predicting advances in endpoint security solutions), ransomware defense posture (see ransomware detection, response, and recovery and predicting the next big ransomware evolution), and monitoring strategy (see next-gen SIEM).
Make “evidence” a product, not a byproduct
The biggest hidden cost in security programs is evidence hunting. Fix it with:
Evidence requirements baked into tickets (completion means evidence attached)
Automated exports (IAM reports, backup test logs, vulnerability trends)
Monthly evidence checks (spot stale artifacts before audits do)
Exception workflow (time-bound, compensating controls, explicit sign-off)
This is also how you keep up with compliance direction and regulatory acceleration (see privacy regulations: emerging global trends (2026–2030) and the evolution lens of GDPR 2.0: predicting the next evolution in data privacy regulations).
Align the program to real teams and real roles
Frameworks collapse when everyone assumes “security owns it.” In reality:
IT owns many operational controls (patching, asset inventory, identity hygiene)
Engineering owns SDLC and deployment integrity
Finance owns approval and payment controls (especially against fraud)
Leadership owns risk acceptance
That’s why role clarity matters—and why organizations formalize operational paths like how to become a cybersecurity manager and executive progression like step-by-step career roadmap to CISO. Even the skills pipeline matters: scaling mature programs requires training talent into consistent practices (see future skills for cybersecurity professionals and cybersecurity certifications of the future).
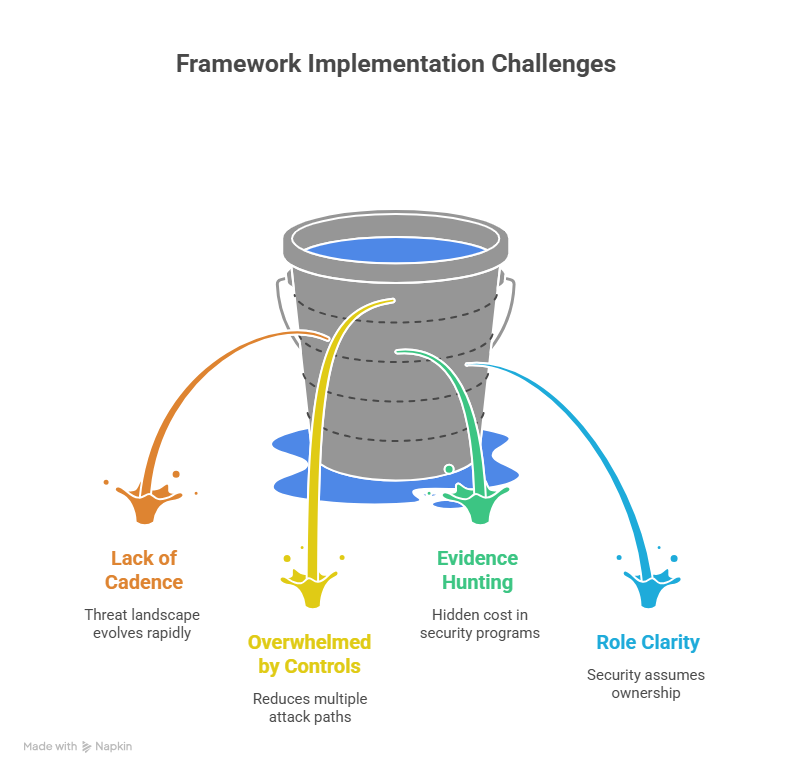
5) The failure patterns that make frameworks useless (and how to fix them)
Failure pattern #1: “We mapped controls,” but nothing changed operationally
Mapping is not security. If your framework project produced spreadsheets but did not improve:
incident response speed,
access hygiene,
detection quality,
patch SLAs,
backup recovery confidence,
then it’s theater.
Fix: choose 10–15 controls that produce immediate outcomes and operationalize them first. Use threat drivers to guide this choice (see top 10 threats by 2030 and sector-specific pressure like healthcare cybersecurity predictions or manufacturing sector cybersecurity).
Failure pattern #2: Policies exist, but exceptions are uncontrolled
Exceptions aren’t inherently bad; unmanaged exceptions are. When exceptions become permanent, they become attacker footholds—especially in identity, cloud, and remote access.
Fix:
Time-bound exceptions with compensating controls
Expiration triggers automatic re-review
Quarterly exception reporting to leadership
This becomes even more critical as zero trust strategies evolve and organizations attempt to enforce least privilege at scale (see predicting the future of zero trust security).
Failure pattern #3: The framework doesn’t reflect cloud and SaaS reality
Traditional control language often assumes static networks. Modern environments are dynamic:
IAM changes constantly
workloads scale automatically
policies are code
misconfigurations can become exposures in minutes
Fix: embed cloud posture controls into your “one control set,” aligned with trend direction (see future of cloud security) and role-level capability building (see how to become a cloud security engineer).
Failure pattern #4: Detection is treated as “having tools,” not “having coverage”
Security teams buy platforms and still miss real attack chains because detection isn’t engineered:
log sources missing,
correlation weak,
alerts noisy,
no validation against attack techniques.
Fix:
define top attack paths and required telemetry
validate use-cases quarterly
measure detection coverage like a product
This aligns with SIEM evolution and next-gen monitoring design (see security information and event management (SIEM): an overview and next-gen SIEM).
Failure pattern #5: Governance isn’t connected to business decisions
If leaders only hear about security during incidents or audits, they will treat it as cost, not risk management.
Fix:
report in business terms (services, downtime, customer impact)
show trend lines (risk going down because controls improved)
connect funding to measurable risk reduction
This becomes non-negotiable as legislation and compliance pressures rise, particularly for small and mid-market organizations (see predicting the impact of cybersecurity legislation on SMBs and the next generation of cybersecurity standards).
6) FAQs
-
Start with an outcome-first structure (NIST-style thinking) to establish minimum operational controls, then formalize your management system (ISO-style discipline) once you can sustain evidence. If governance and accountability are your biggest blockers, introduce COBIT concepts early to define ownership and decision rights. Anchor priorities to real threat direction (use top 10 threats by 2030 to avoid building a program for yesterday).
-
Yes—and many organizations should at first. Treat ISO as a discipline (scope, ownership, evidence, continuous improvement) before treating it as a badge. If certification is the goal, you’ll progress faster by building an evidence system now (see predicting future cybersecurity audit practices).
-
Cap mapping time. Build your “one control set,” operationalize the highest-leverage controls, and only map what you need for external requirements. Use a detection-and-response lens to force real outcomes (see ransomware detection, response, and recovery and monitoring guidance like SIEM overview).
-
Evidence is not a screenshot folder. It’s repeatable exports: IAM access reports, policy-as-code checks, CSPM findings with remediation SLAs, backup restore test logs, and validated detection use-case results. If your evidence can’t be reproduced next month by someone else, it’s not evidence—it’s a one-time story. Use cloud trend signals to shape what you collect (see future of cloud security).
-
At minimum quarterly, because threats and environments change faster than annual cycles—especially across identity, AI-driven attacks, and ransomware evolution (see ai-powered cyberattacks and predicting the next big ransomware evolution). Your reassessment doesn’t need to be huge; it needs to be honest and tied to control health.
-
Frameworks scale through people who can run processes consistently. Invest in role clarity and growth paths: operational analysts who can maintain control health and detection quality (see SOC analyst guide (2025)), leaders who can drive cross-team remediation (see cybersecurity manager pathway), and long-term strategic owners who can align risk to business outcomes (see CISO roadmap).