
Security Audits: Processes and Best Practices
Security audits don’t fail because teams “don’t care about security.” They fail because evidence is scattered, controls are implemented but not provable, ownership is unclear, and everyone discovers too late that the audit is really testing operational discipline—not intent. A high-quality audit program turns security from a collection of tools into a repeatable system: scoped risks, measurable controls, testable evidence, and fast remediation loops. This guide shows you how to run audits that hold up under scrutiny, reduce disruption, and produce outcomes leadership will actually fund.
1) What a Security Audit Really Proves (and What It Doesn’t)
A security audit is not a vibes-check and it’s not a “gotcha.” It’s a structured way to answer one question: Can you consistently demonstrate that your controls reduce risk the way you claim? If you can’t prove it with evidence, the audit treats it as unreliable—no matter how confident the team feels.
The biggest audit misconception is treating it like a once-a-year exam. A modern audit is closer to an operating model: controls, logs, tickets, approvals, and system configurations that can be traced end-to-end. If your environment is cloud-heavy, auditability becomes inseparable from how you design identity, logging, and change management—especially when you’re scaling toward roles like a cloud security engineer and moving toward modern patterns like zero trust.
What an audit does prove:
Controls exist in writing (policy/standard/procedure) and in practice (system state + evidence).
Controls are owned, measurable, and consistently executed.
The organization can detect and respond—especially to threats like ransomware and emerging attack patterns discussed in future threat forecasting.
What an audit doesn’t prove:
That you’re “secure.” It proves you can evidence your security posture against a standard.
That tools equal controls. A SIEM you don’t tune won’t satisfy “monitoring”; it becomes a liability (see SIEM overview).
That compliance equals resilience. Audits can validate readiness, but attackers exploit what’s real, not what’s documented (context: threats predicted by 2030).
If you want audits to stop being a fire drill, treat them like a product: define requirements (standard), build controls (implementation), generate telemetry (evidence), run tests (assurance), ship fixes (remediation). That mindset is exactly what’s discussed when organizations anticipate future audit practices and regulatory pressure in compliance trend predictions.
2) Audit Planning: Scope, Criteria, and Evidence Map
High-performing teams win audits before fieldwork begins. Planning is where you eliminate chaos: define what you’re being measured against, what’s in scope, and exactly which evidence proves each control. If you skip this, the audit becomes a scavenger hunt—and you’ll feel that pain most in cloud and identity, where misconfigurations and “invisible drift” are common (see future of cloud security and the reality of evolving threats like AI-powered attacks).
Step 1: Define the “audit claim”
Every audit is testing a claim such as: “We manage privileged access,” “We monitor and respond,” or “We control change.” Tie claims to a framework (SOC 2, ISO 27001, NIST, CIS), then map each claim to controls.
If you’re in regulated or fast-evolving environments, your claim set should align with the direction of privacy regulations, the likely evolution of GDPR 2.0, and industry-specific requirements like finance security trends.
Step 2: Set scope like an engineer, not a lawyer
Scope should be unambiguous and testable:
Systems: production, staging, endpoints, SaaS, cloud accounts/subscriptions.
Data: customer data, employee data, financial data, regulated data.
Locations/teams: internal IT, SOC, DevOps, vendor-managed systems.
Your scope should also reflect your threat model. If ransomware is your top business risk, scope needs strong IR, backup, and restore testing (see ransomware evolution plus practical ransomware detection/response).
Step 3: Build an evidence map (the “audit packet” blueprint)
An evidence map is a spreadsheet or control matrix that lists:
Control objective (what you’re trying to achieve)
Control owner (who is accountable)
System of record (where evidence comes from)
Evidence artifact (exact export/report/screenshot)
Frequency (monthly/quarterly/continuous)
Test method (inquiry, observation, inspection, re-performance)
This is where teams usually lose time: they collect “security proof” but not “audit-grade evidence.” Audit-grade evidence is time-bounded, read-only, traceable, and consistent. For monitoring controls, that often means pulling case records from tooling used by your SOC—work that aligns with the discipline in SOC analyst paths and how teams mature into leadership roles like SOC manager.
Step 4: Decide sampling and timelines up front
Auditors test samples. If you don’t define sampling windows early, you’ll be forced to recreate history. Set:
Audit period (e.g., last 6–12 months)
Sample size rules (e.g., 25 access changes, 10 incidents, 15 vendor reviews)
What counts as “complete” for each sample (required fields and timestamps)
A hidden best practice: pre-validate a small sample internally. Treat it like a dress rehearsal. This method matches the operational maturity described in next-gen SIEM discussions where visibility and evidence quality become strategic.
3) Fieldwork: Testing Controls Without Breaking the Business
Fieldwork is where your audit planning gets stress-tested. The goal isn’t to “look good.” The goal is to demonstrate that controls produce consistent outcomes under real conditions—especially in areas attackers actually exploit: identity, vendor access, cloud misconfigurations, and response gaps (see top 2030 threats and the rising risks from deepfake threats).
The four audit test methods (and how to win each)
Inquiry (asking people): You win by having documented procedures that match actual practice.
Observation (watching a task): You win by showing repeatable steps and consistent outcomes.
Inspection (reviewing artifacts): You win with timestamped exports, not anecdotes.
Re-performance (auditor repeats the control): You win when controls are automatable and deterministic.
For technical controls, auditors often want to see:
Monitoring and detection proof: tie to SIEM, IDS deployment, and response case notes.
Access controls and cryptography proof: tie to PKI and encryption standards.
Remote access controls: tie to VPN limitations and conditional access maturity.
Evidence patterns that reduce audit friction
Exports > screenshots when possible. Screenshots are fragile without metadata.
Evidence should show: who, what, when, approval, execution, verification.
Use read-only links or signed exports where feasible; otherwise capture the “audit chain” (ticket ID → change record → deployment → validation).
Testing the controls auditors care about most
Identity and access
Auditors focus here because identity failures translate directly into breaches (phishing, token replay, OAuth consent abuse). Your evidence should show:
MFA enforcement coverage and exception process
Privileged access approvals and periodic reviews
Termination deprovision timelines
Service account governance (owners, rotation, least privilege)
This intersects directly with career-grade capability: if your team is building maturity, your pathways look like ethical hacking career roadmaps and governance roles like cybersecurity compliance officer where audit-readiness becomes a core skill.
Logging and monitoring
Auditors don’t just want “we have a SIEM.” They want:
A list of required log sources (cloud, IAM, endpoints, key apps)
Proof of ingestion and retention
Proof alerts are triaged consistently with documented decisions
If monitoring is immature, you’ll fail on consistency: “We saw it” is not “We can prove we saw it.” Modern audit direction is moving toward continuous assurance (see predicting audit practices).
Incident response
A great IR plan is worthless if you can’t prove it’s exercised. Auditors want tabletop results, action items, and closure. For ransomware readiness, auditors increasingly expect recovery evidence, not just backup existence (connect your program to ransomware response and future evolution scenarios like ransomware by 2027).
Third-party risk
Vendor risk is audit oxygen now. You need:
Vendor tiering and risk ratings
Contractual security requirements
Review cadence
Offboarding proof for vendor access
This becomes even more critical as supply chain risks rise (frame it alongside future standards evolution in next-generation standards).
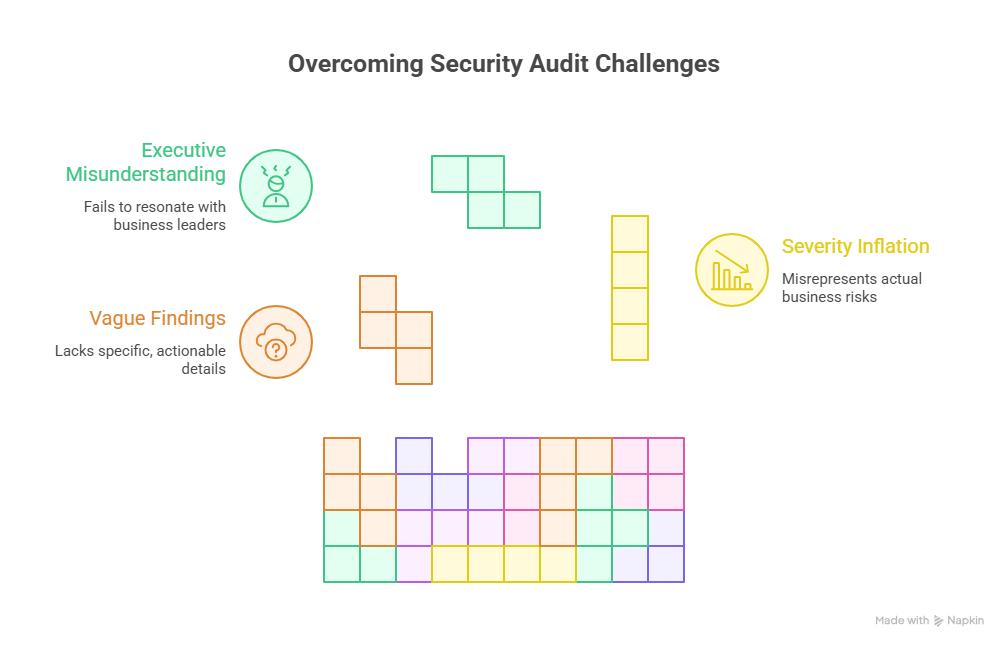
4) Reporting: Turning Findings Into Decisions Executives Fund
A report that only lists problems is a missed opportunity. The point of audit reporting is to translate technical gaps into decision-ready risk: what’s wrong, what it enables, what it costs, and what to do first. If you do this well, audits become a lever for budget, headcount, and tooling—especially when leadership is already worried about future risk curves like AI-driven cyberattacks and identity-centric threats like deepfake-enabled fraud (see deepfake preparedness).
A high-signal finding structure (that stops debates)
Each finding should include:
Condition: what you observed (facts + evidence reference)
Criteria: what requirement/control it violates (framework mapping)
Cause: why it happened (process, tooling, ownership)
Impact: what risk it creates (specific attack/incident scenarios)
Recommendation: what to change (actionable, not generic)
Owner + due date: single accountable party and timeline
The difference between “we lack logging” and “we lack logging for authentication and admin actions in cloud accounts, preventing detection of token replay and consent abuse” is the difference between a vague worry and a funded project (tie to broader threat narratives like evolution of threats and sector pressures like government/public sector trends).
Severity that reflects business reality
Avoid severity inflation. Use a severity model that connects to:
Likelihood (exposure, exploitability, control maturity)
Impact (data loss, downtime, fraud, regulatory outcomes)
Detectability (whether you would notice in time)
If your business is in energy or utilities, severity logic should reflect the environment (see energy & utilities recommendations). For healthcare, reflect downtime and safety impacts (see healthcare predictions). For retail, reflect payment fraud and customer trust impacts (see retail e-commerce landscape).
The “audit narrative” executives actually understand
Executives respond to:
Blast radius
Time-to-detect
Time-to-recover
Fraud pathways
Regulatory exposure
So write findings like a story of consequences:
“Admin access is not recertified, enabling privilege creep that increases blast radius.”
“Key log sources aren’t retained, blocking investigations and extending incident dwell time.”
“Vendor access isn’t tiered, creating supply chain compromise exposure.”
Then connect recommended fixes to recognizable security programs: maturing your SOC (see SOC analyst), improving controls for endpoint and network threats (see DoS mitigation), and aligning with emerging standards (see next-generation standards).
5) Remediation and Continuous Assurance: Staying Audit-Ready
The audit ends, but the risk doesn’t. The strongest audit programs treat remediation as a pipeline: prioritize fixes that reduce real exposure, verify effectiveness, and keep evidence “always-on.” This is exactly where many organizations fail: they close findings in spreadsheets but don’t change how work happens—so the same issues return next year.
Build a remediation backlog like a product roadmap
For each finding, create:
Work items (tickets with acceptance criteria)
Owners (security + engineering + IT)
Dependencies (identity team, DevOps, vendor procurement)
Proof of fix (what evidence will show it’s resolved)
Then implement a verification cadence: the auditor’s job is to test controls; your job is to test your own fixes before someone else does. This is the spirit behind anticipating the future of audits and assurance (see audit practice innovations).
Prioritize “control leverage” fixes
Some fixes reduce multiple risks at once:
Identity hardening (MFA, conditional access, privileged governance) reduces breach likelihood across the board—especially as identity takeover becomes a dominant theme in future threat landscapes (see top threats by 2030).
Logging coverage + consistent triage upgrades detection and audit evidence simultaneously (align to SIEM).
Backup restore testing improves resilience and audit proof for ransomware readiness (see ransomware detection and recovery).
Move from annual evidence to continuous evidence
If your evidence collection is manual, you’ll always be behind. Build “evidence pipelines”:
Automated exports (identity reports, vulnerability trends, patch status)
Monthly control checks (privilege recerts, vendor access reviews)
Standard evidence packs per control (same format each cycle)
This aligns with where the industry is heading: more automation, more specialization, and higher expectations for measurable competence (see demand for specialized roles and how the workforce evolves with automation in robots vs analysts).
Don’t ignore vendor and sector-specific audit risk
Auditors increasingly expect you to understand your industry threat environment:
Manufacturing: OT/ICS intersections and supply chain (see manufacturing trends)
Finance: fraud pathways and compliance scrutiny (see finance predictive insights)
Government/public sector: governance rigor and accountability (see public sector analysis)
Audit readiness is not just defensive; it’s career capital. If you’re building your path, audit competence supports routes into cybersecurity auditor roles, management pathways (see cybersecurity manager pathway), and executive tracks like CISO roadmaps.
6) FAQs: Security Audits
-
An audit tests you against defined criteria and demands evidence that controls operate consistently. An assessment is broader and can be advisory. If you want audit-grade monitoring proof, align your telemetry and workflows with practices outlined in SIEM operations and structured response programs like ransomware detection/response.
-
Evidence that is time-bounded, traceable, and tied to a control owner: exports from identity systems, ticket histories, logs with retention configs, change approvals, and case notes. If your environment is cloud-first, your evidence story should match the realities described in the future of cloud security and modern access models like zero trust.
-
Because tools aren’t controls unless they’re configured, governed, and provable. A SIEM without consistent triage notes, or MFA with undocumented exceptions, looks weak under audit. This gap is increasingly exploited by real attackers too, as highlighted in 2030 threat predictions and evolving adversary techniques in AI-driven attacks.
-
Tier vendors by risk, define what systems and data they touch, and require evidence at the tier level (not one-size-fits-all questionnaires). Vendor access control should be auditable the same way internal privileged access is. This matters more as standards and expectations evolve (see next-gen standards predictions).
-
Create an evidence map, standardize evidence packs, and fix the highest-leverage gaps: identity governance, logging coverage/retention, and restore testing. Those changes reduce both audit friction and real breach risk—especially against the ransomware and identity trends described in ransomware evolution by 2027 and deepfake-enabled fraud.
-
Auditors want explicit configuration proof and governance: encryption settings, KMS policies, rotation evidence, access controls, and audit logs. Tie your narrative to fundamentals like PKI components and practical standards coverage in encryption methods.
-
Audit readiness is cross-functional: security governance owns the control framework, engineering/IT owns implementation, and SOC owns monitoring/response proof. That’s why audit competence shows up across career paths—from SOC analyst to compliance officer to CISO progression.