
Cybersecurity Incident Response Report: Effectiveness & Improvements (2026-2027 Original Data)
Cybersecurity incidents do not become expensive only because attackers get in. They become expensive because response quality collapses under pressure: alerts pile up, ownership blurs, logs are incomplete, leadership wants instant answers, legal timing gets missed, and the team burns hours proving what happened instead of containing it. That is where strong programs separate themselves from security theater.
This report breaks incident response effectiveness into the operational decisions that actually change outcomes in 2026-2027: triage speed, evidence quality, containment discipline, escalation clarity, recovery readiness, and post-incident learning. If your team keeps asking why the same mistakes reappear in different incidents, this is the layer to fix.
1. Why incident response effectiveness is now a board-level performance issue
Incident response is no longer a narrow SOC problem. It is a business resilience function that determines whether an intrusion stays isolated or becomes an enterprise-wide operational failure. Teams that still treat response as a checklist underinvest in the capabilities that truly matter: validated escalation paths, clean asset context, durable logging, role-based decision authority, and recovery discipline. That is why organizations studying security audits and best practices, maturing around NIST, ISO, and COBIT frameworks, improving incident response plan development and execution, and upgrading SIEM strategy consistently outperform those that focus only on tooling.
The hard truth is that many security teams do not fail during the attack. They fail during the handoff between detection and action. Analysts identify suspicious behavior, but endpoint owners cannot confirm scope. Legal wants evidence preserved, but operations starts reimaging too early. Executives ask whether customer data was touched, but identity logs are incomplete. That is why mature organizations align response with cyber threat intelligence collection and analysis, tighter intrusion detection system deployment, better vulnerability assessment techniques and tools, and realistic ransomware detection, response, and recovery muscle.
In 2026-2027, effectiveness is increasingly judged by four executive-facing questions: How fast did we know it was real? How much damage did we stop? How accurately did we explain impact? How confidently did we prove improvement afterward? Programs that cannot answer those questions with evidence struggle to justify budget, talent, or authority. That is one reason professionals exploring the future cybersecurity job market, advancing toward a SOC analyst pathway, moving from SOC analyst to SOC manager, or planning the route to cybersecurity manager are being evaluated less on theory and more on incident command credibility.
A weak response program creates expensive downstream pain points that leadership feels immediately: repeated false positives, uncontained lateral movement, confused communication, excessive downtime, regulator anxiety, customer mistrust, and analyst attrition. A strong one creates leverage. It shortens uncertainty, protects evidence, reduces blast radius, and produces clean lessons that strengthen architecture. That leverage compounds when paired with next-gen SIEM direction, better endpoint security trends, stronger zero trust innovation planning, and sharper future skills for cybersecurity professionals.
| Checkpoint | Why It Matters | What Strong Teams Do | Common Failure Pattern |
|---|---|---|---|
| 1. Alert validation speed | Cuts wasted escalation time | Triage with asset, identity, and threat context in minutes | Analysts chase noisy alerts without enrichment |
| 2. Incident severity accuracy | Prevents underreaction or chaos | Uses documented severity criteria tied to business impact | Severity labels are subjective and inconsistent |
| 3. Escalation ownership clarity | Avoids paralysis during the first hour | Defines who leads, approves, informs, and documents | Everyone joins the call; no one truly owns the incident |
| 4. Asset criticality mapping | Improves prioritization | Links alerts to crown-jewel systems and dependencies | Teams cannot tell if the affected host actually matters |
| 5. Identity visibility | Reveals privilege abuse and lateral movement | Correlates users, service accounts, MFA, and admin events | Compromised credentials remain invisible too long |
| 6. Log completeness | Supports confident scope decisions | Collects endpoint, cloud, email, network, and identity evidence | Missing data forces guesswork |
| 7. Evidence preservation | Protects legal and forensic value | Captures volatile artifacts before remediation | Systems are wiped or rebooted too early |
| 8. Containment decision speed | Reduces attacker dwell time | Uses preapproved containment options by scenario | Teams debate isolation while attackers keep moving |
| 9. Containment precision | Limits business disruption | Targets affected accounts, hosts, tokens, or segments cleanly | Overbroad shutdowns damage operations |
| 10. Cloud response readiness | Improves action in modern environments | Has playbooks for IAM abuse, storage exposure, and workload compromise | Legacy IR plans barely cover cloud events |
| 11. Third-party coordination | Accelerates vendor-linked incidents | Maintains response contacts, SLAs, and shared evidence paths | Critical vendors are unreachable when needed most |
| 12. Communication discipline | Reduces confusion and rumor | Separates technical updates, executive summaries, and legal messaging | Mixed messages distort perceived impact |
| 13. Executive decision support | Speeds high-stakes choices | Frames risk, options, tradeoffs, and confidence levels clearly | Leaders receive raw telemetry instead of decisions |
| 14. Ransomware readiness | Determines survival under pressure | Practices isolation, backup validation, and extortion workflows | Recovery assumptions are untested |
| 15. Insider threat handling | Requires tighter evidence and discretion | Coordinates HR, legal, identity, and monitoring carefully | Premature confrontation destroys evidence |
| 16. Email incident workflow | Stops user-driven spread | Automates mailbox search, URL takedown, and user warning paths | Phishing messages remain live too long |
| 17. Threat intelligence fusion | Improves prioritization and attribution confidence | Maps indicators and TTPs to real adversary behavior | Feeds are collected but never operationalized |
| 18. Forensic handoff quality | Preserves investigation momentum | Packages timelines, artifacts, and hypotheses cleanly | Context is lost between teams |
| 19. Recovery validation | Prevents reinfection or false closure | Tests restored systems, credentials, and control coverage | Systems return without confirming root cause removal |
| 20. Root cause depth | Creates meaningful improvement | Tracks process, architecture, identity, and human failures | Reviews stop at “phishing email clicked” |
| 21. Mean time to contain | Measures operational effectiveness | Reviews containment time by scenario and business tier | Only detection speed is measured |
| 22. Cross-team drill frequency | Reveals hidden bottlenecks | Runs tabletop and live simulations with IT, legal, and comms | Plans exist only on paper |
| 23. Playbook usability | Supports stressed responders | Keeps steps concise, scenario-specific, and decision-oriented | Playbooks are verbose and ignored during crises |
| 24. Analyst fatigue resistance | Protects judgment quality | Uses automation, prioritization, and rotation discipline | Burned-out responders miss key indicators |
| 25. Post-incident governance | Turns lessons into change | Assigns owners, deadlines, and proof of remediation | Lessons learned stay trapped in slide decks |
| 26. Improvement reporting | Builds trust with leadership | Shows measurable control, speed, and readiness gains | Security cannot prove it improved after incidents |
2. The 2026-2027 effectiveness model: what separates resilient response teams from reactive ones
The strongest incident response teams are not necessarily the ones with the largest budgets. They are the ones that can move from weak signal to confident action without drowning in ambiguity. That requires four layers working together: detection quality, decision quality, execution quality, and learning quality. Many organizations invest heavily in detection and underinvest in the other three. The result is a modern dashboard sitting on top of an immature response engine. Teams buying top network monitoring and security tools, comparing best DLP software, reviewing cloud security tools, or evaluating application security platforms need this reminder constantly: tools do not close incidents; coordinated teams do.
Detection quality means alerts arrive enriched enough to support immediate thinking. If the team sees suspicious activity but lacks asset value, privilege context, internet exposure, owner assignment, and recent change history, that alert is far less useful than it looks. Mature teams pull from access control model design, stronger PKI foundations, durable encryption standards planning, and better firewall configuration strategy because preventive architecture directly influences response quality.
Decision quality is where many programs quietly collapse. The team may technically detect compromise, but if nobody can rapidly decide whether to disable a privileged account, isolate a sensitive workload, shut down a partner connection, or trigger legal notification review, attackers gain time. Decision quality improves when leadership roles are practiced, containment thresholds are predefined, and every major scenario has a risk-based branch structure. That is also why teams studying future compliance trends, tracking privacy regulation evolution, anticipating GDPR 2.0 shifts, and preparing for next-generation cybersecurity standards are often better positioned during high-impact incidents.
Execution quality determines whether the chosen action actually works. A beautiful playbook is worthless if the SOC cannot isolate cloud workloads, identity cannot revoke sessions fast enough, backup teams cannot verify restore integrity, or communications cannot keep leadership aligned. In other words, execution quality is where architecture, people, process, and business dependencies collide. Teams preparing for cloud security futures, studying AI-powered cyberattack evolution, anticipating deepfake-driven threats, and watching top cybersecurity threats predicted by 2030 understand that execution must evolve as adversary tradecraft evolves.
Learning quality is the most neglected layer and the one that determines whether a program matures or merely survives. Teams that conduct shallow postmortems usually fix indicators, not systems. They remove a malicious binary, close the ticket, and move on without asking why segmentation failed, why access was too broad, why backups were unverified, or why decision authority was slow. That is exactly how the same weakness returns wearing a different adversary costume. Organizations serious about growth learn from predictive cybersecurity audit changes, benchmark against top cybersecurity companies worldwide, study managed security service provider models, and keep talent sharp through a global directory of training providers.
3. Where incident response programs break down most often and why improvements stall
Most failed response programs do not suffer from a complete absence of effort. They suffer from fragmented maturity. One team has a decent playbook. Another has strong analysts. A third has useful tooling. But no one has stitched those assets into an integrated response capability that works under pressure. This is why organizations can spend heavily and still perform poorly during major incidents.
The first recurring breakdown is triage overload. Analysts receive more alerts than they can seriously evaluate, so they start optimizing for throughput rather than quality. In that environment, subtle signs of identity misuse, cloud control-plane abuse, and cross-environment attacker movement are easier to miss. The answer is not merely “more analysts.” It is better prioritization logic, stronger enrichment, scenario-specific detections, and narrower escalation thresholds. Teams facing this pain often benefit from revisiting threat intelligence analysis, strengthening SIEM operations, improving IDS deployment, and exploring how automation will shape the cybersecurity workforce.
The second breakdown is incomplete visibility. Teams cannot respond well to what they cannot reconstruct. Missing logs, blind spots in SaaS activity, poor asset inventories, unmanaged identities, and fragmented cloud telemetry make scoping slow and politically dangerous. Security leaders then get pressured to speak confidently without enough evidence. That is a credibility trap. The fix is to treat telemetry completeness as a resilience control, not a technical luxury. It also helps to benchmark against best cybersecurity solutions for SMBs, cybersecurity solutions for small businesses, manufacturing security solutions, and energy-sector cybersecurity providers, because sector-specific operational realities change visibility needs.
The third breakdown is containment hesitation. Some teams are terrified of business disruption, so they wait too long to isolate assets or disable access. Others overreact and shut down too much, causing self-inflicted outage pain. Both are symptoms of weak decision engineering. Mature teams predefine containment choices by scenario, business tier, and confidence threshold. They know when to revoke tokens, block lateral paths, disable external access, or segment workloads without improvising the entire response from scratch. These teams also learn from DoS mitigation practices, botnet disruption methods, VPN security tradeoffs, and data loss prevention strategy.
The fourth breakdown is recovery illusion. Many organizations think they are done once systems come back online. That is dangerous. Recovery without validation can restore the same trust paths, the same persistence vectors, the same overprivileged accounts, or the same unpatched exposures that enabled compromise. Recovery has to verify integrity, not just availability. That means credential hygiene, configuration review, backup trust, control retesting, and business workflow confirmation. Teams preparing for cybersecurity in healthcare, finance-sector risks, government-sector security futures, and education-sector threat evolution know recovery standards must reflect sector stakes.
Finally, improvements stall when “lessons learned” never become owned remediation. A post-incident review that produces no deadlines, no accountable owners, no proof requirements, and no governance follow-up is not a learning system. It is grief processing disguised as improvement.
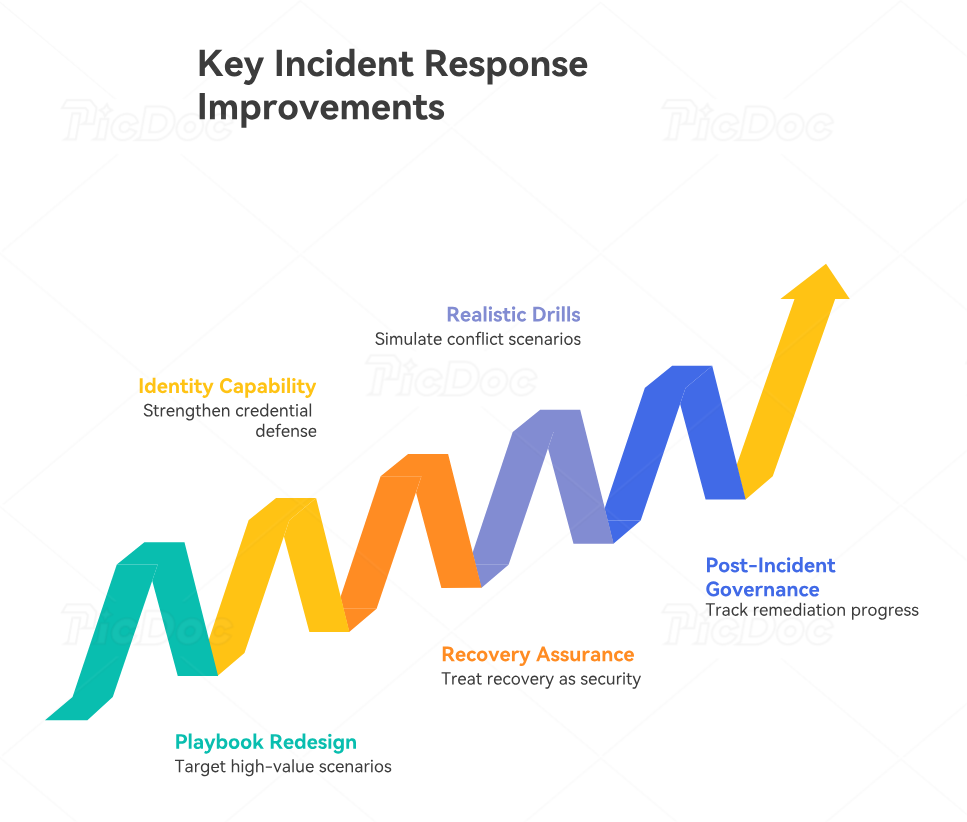
4. The highest-value improvements organizations should prioritize in 2026-2027
The best response improvement plans do not try to fix everything at once. They target the bottlenecks that create the biggest operational drag during real incidents. For most organizations, the first high-value improvement is scenario-based playbook redesign. Generic playbooks are usually too broad to be useful under stress. Teams need concise workflows for ransomware, business email compromise, cloud identity abuse, privileged account misuse, data exfiltration, malicious insider behavior, third-party compromise, and high-confidence malware execution. That redesign becomes even stronger when informed by cloud security engineering pathways, IoT security specialist roadmaps, ethical hacking skill paths, and penetration tester to consultant progression.
The second high-value improvement is identity-centric response capability. Attackers increasingly win through credentials, sessions, roles, tokens, delegated permissions, and trust relationships rather than loud malware alone. If your response program cannot rapidly answer which accounts were affected, what privileges they held, what sessions remain active, and which business systems trust them, your containment speed will remain weak. This is where better access control strategy, stronger privileged access management reviews, improved cloud security tooling, and tighter security framework alignment create outsized gains.
The third high-value improvement is recovery assurance. Recovery should be treated as a security function, not merely an IT operations outcome. Teams need restore validation procedures, trust re-establishment criteria, credential reset sequencing, data integrity testing, and checkpoint-based executive signoff. This matters especially in ransomware, destructive malware, insider abuse, and infrastructure compromise. Organizations confronting ransomware evolution predictions, watching AI-driven defense innovation, studying blockchain-related cybersecurity innovations, and preparing for remote cybersecurity career shifts need recovery validation processes that work across distributed teams and hybrid infrastructure.
The fourth high-value improvement is cross-functional drill realism. Tabletop exercises help, but many are too polite. Real value comes from simulations that force conflict, uncertainty, escalation pressure, legal ambiguity, incomplete evidence, and time-sensitive business decisions. If your drill never tests who can approve a vendor disconnect, who communicates with customers, who authorizes law-enforcement outreach, or who decides whether backups are trustworthy, your drill is underpowered. Teams exploring cybersecurity instructor career paths, building toward cybersecurity curriculum developer roles, or planning for CISO leadership tracks should pay close attention here because leadership maturity is forged during ambiguity, not lectures.
The fifth high-value improvement is post-incident governance with proof. Improvement should not end with a meeting. It should produce a remediation register, deadline ownership, risk-ranked backlog, control-verification plan, and executive progress reporting. Without that, incident response becomes a reactive service instead of a strategic improvement engine.
5. How to turn this report into a measurable incident response improvement roadmap
A strong roadmap starts by refusing vanity metrics. Counting incidents, tickets, or alerts tells leadership very little about response strength. Better metrics include mean time to validate, mean time to escalate, mean time to contain, evidence completeness by scenario, percentage of incidents with preserved forensic artifacts, recovery validation success rate, repeat-cause frequency, and remediation closure rate after postmortem. These metrics connect directly to operational pain. They also provide better guidance for teams comparing security awareness platforms, learning from cybersecurity podcasts, using YouTube learning channels, or strengthening fundamentals through top cybersecurity books.
Step one is baseline mapping. Score your current maturity across the 26 checkpoints in the matrix above and force honest evidence for every score. Do not accept “we have a process” as proof. Ask to see the playbook, the drill record, the decision log, the logging coverage map, the restoration validation checklist, and the remediation tracker. This evidence-based posture aligns well with cybersecurity audit careers, compliance officer pathways, and security manager to director roadmaps because senior growth depends on proving control quality, not merely describing it.
Step two is scenario prioritization. Do not build the roadmap around generic anxiety. Build it around the incident types most likely to create material business harm in your environment. For some organizations that means ransomware. For others it means business email compromise, cloud account takeover, SaaS data exposure, insider abuse, application compromise, or vendor-linked intrusion. Sector-specific reading helps here, including retail and e-commerce risk forecasts, manufacturing threat trends, nonprofit cybersecurity provider guidance, and financial-services cybersecurity firm analysis.
Step three is bottleneck selection. Pick the few response failures that multiply damage across multiple scenarios. Visibility gaps, identity blind spots, slow containment approvals, weak recovery validation, and poor remediation governance are usually better targets than cosmetic process edits. This is where security leaders should think like operators, not presenters.
Step four is capability packaging. Bundle improvement work into operationally coherent releases: telemetry and enrichment, scenario playbooks, identity containment, executive communications, recovery assurance, drill design, and post-incident governance. Packaging work this way helps teams sequence change without overwhelming staff already carrying incident load.
Step five is proof-based review every quarter. If an improvement cannot be demonstrated in a drill, a real incident, or a control test, it is not mature yet. This discipline is what converts incident response from emergency reaction into a compounding business capability.
6. FAQs
-
The most meaningful way is to measure whether the team reduces uncertainty and damage fast enough to support confident business decisions. That means tracking validation speed, escalation clarity, containment time, evidence completeness, recovery assurance, and whether post-incident fixes actually close repeat weaknesses. Metrics disconnected from decision quality create false confidence.
-
Because tools can detect, enrich, correlate, and automate, but they cannot resolve unclear ownership, slow approvals, missing evidence, or weak recovery discipline on their own. Many programs are technologically modern and operationally immature. The gap appears the moment real pressure hits.
-
Both matter, but containment speed usually determines whether damage remains limited. Fast detection followed by slow action still gives attackers room to escalate. The mature goal is not merely to know earlier. It is to act earlier with enough precision to reduce blast radius without triggering unnecessary disruption.
-
Stopping at the superficial cause. “A phishing email was clicked” is not a root cause. The deeper questions are why access was overly trusted, why identity signals were weak, why detection lagged, why containment approvals were slow, and why recovery assurance was incomplete. Real improvement starts below the obvious layer.
-
At minimum after major incidents, major architecture changes, meaningful regulatory changes, and recurring drills. In fast-changing environments, quarterly review is healthier than annual review. A playbook that no longer matches cloud workflows, identity architecture, business dependencies, or executive reporting needs becomes dangerous during stress.
-
Start with visibility, ownership, and scenario-specific containment. If you cannot see enough, decide fast enough, or act precisely enough, other improvements will not land well. Build a clean foundation first, then expand into recovery assurance, forensic readiness, executive communication, and post-incident governance.
-
Because many teams still treat recovery as an IT restoration exercise rather than a security trust-restoration exercise. Systems coming back online does not prove the threat is gone. Recovery needs verification of credentials, persistence removal, control integrity, data trust, and business workflow safety.